3D视频系统中深度图的估测方法的研究(3)
技术应需求而发展,在此大背景下,深度估测作为3D图像技术的核心一环,也是一大难题,对深度估测方法的研究也就成为了当今最热门的领域之一。通常,深度估测分为局部和全局两类方法。大多数深度估计是基于能量最小化框架的全局方法,本文所提的由时差估计得到深度估计的方法是较为常见并且经典的一种方法。
1.3国内外研究现状
1.4研究方法
因为对深度估计的领域不是很了解,所以首先,我阅读了一些关于深度估计的的文献资料,通过学习逐渐了解如何获得深度图,对深度图的产生原理有了比较详细的认识。其中,我特别注意深度估计的算法,比较了一下他们的优势与不足。
接下来,我学习使用深度估计参考软件DERS,我翻译了它的部分说明书并先通过读说明书了解它。通过设断点,分别来了解了关键语句的作用,对整个DERS有了一个感性的认识。熟练软件后,我利用三段不同视点的视频,处理产生对应的深度图像,进行了实践。虽然不能说自己已经将其中所有的代码都已看懂,但是关键部分的代码,特别是涉及到深度估测算法的部分,我还是了解地较为详尽。
结合自己所阅读的参考文献,我了解一些现有深度估测算法的不足,找出了问题,想尝试可以改善算法。但是这毕竟是此研究领域的一大难题,我目前尚不具备自己改进算法的能力,这也是我此次研究的一个遗憾。
2. 3D视频深度图的估测研究
2.1 视差与深度估测
2.1.1 视差法估测深度原理
首先,我们可以从生活常识来看这个原理。在小学时我们做过这样一个实验:闭上一只眼睛后,尝试对准两个铅笔的笔尖,结果怎么都对不上。这是为什么呢?当我们的两眼同时注视一个物体时,物体会分别在左右眼的视网膜上形成两个图像,但由于左右眼是有一定间隔的,左眼可以看到的图像略偏左侧,右眼可以看到图像略偏右侧,因此两个图像并不完全相同,不能完全重合。这样视觉图像传入大脑,经过大脑的合成、判别,使物体产生了空间的深度感。这样我们便要想一下,左右眼视图唯一的不同就是它们有左右的位置平移,既然大脑可以把这视差信息转化为深度信息,那我们把眼睛换成摄像机,大脑换成计算机,是不是也可以能够将视差信息转化为深度信息。
事实上,这是可行的。如图2.1所示。
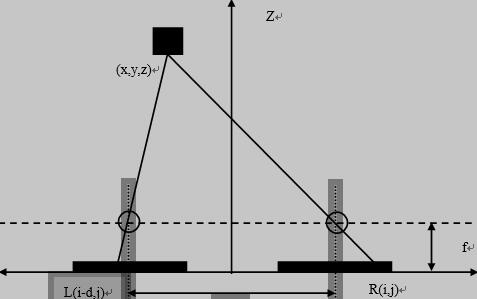
图2.1 立体投影原理图
图中,f是相机镜头的焦距,T是两个相机的间距。这里假设两个摄像机焦长相同,基线宽度为摄像机光学中心之间的距离。其中,两个相机和人眼一样是平行放置的,对同一物体在焦平面上成像。这里我们把左侧相机成的像用CL表示,右相机成的像用CR表示,这两幅图都拍摄到了物体上一点A,A在CL与CR上的位置只存在水平平移,那我们把这两幅图像重合,就可以得到这水平位置差,即我们想要找到的视差。